Maximizing Model Performance: An In-Depth Guide to Hyperparameter Optimization in Machine Learning




Photo by Clément Hélardot on Unsplash
Introduction
Hyperparameters play a crucial role in determining the performance of a machine learning model. The right set of hyperparameters can result in a highly accurate and robust model, while the wrong set of hyperparameters can lead to poor performance and overfitting. In this blog, we will be exploring the different techniques used for hyperparameter optimization in machine learning.
Hyperparameters vs Parameters
Before diving into the different hyperparameter optimization techniques, it is important to understand the difference between hyperparameters and parameters. In machine learning, parameters are the variables that are learned during the training process, such as weights and biases in a neural network. Hyperparameters, on the other hand, are the variables that are set prior to the training process and remain constant throughout the training process. Examples of hyperparameters include learning rate, number of hidden layers, and batch size.
Why is Hyperparameter Optimization Important?
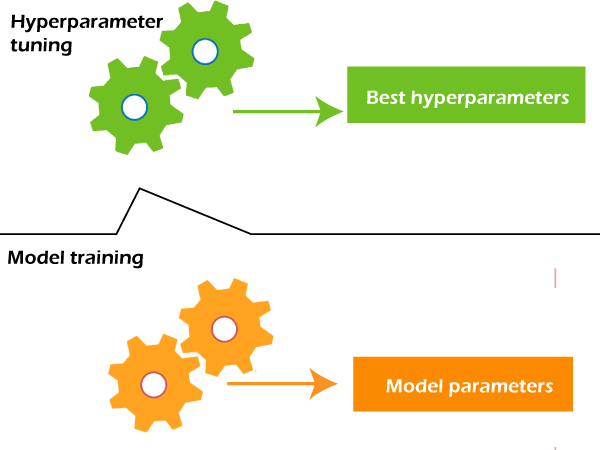
Image Source: link
Hyperparameter optimization is important because the performance of a machine learning model is heavily dependent on the hyperparameters. In some cases, a small change in the hyperparameters can result in a significant improvement in performance. Additionally, the best set of hyperparameters for one problem may not be the best for another problem. Hence, it is essential to optimize the hyperparameters for each problem individually.
Hyperparameter Optimization Techniques
Grid Search
Grid search is a simple and straightforward technique for hyperparameter optimization. In grid search, a grid of hyperparameters is defined and the model is trained and evaluated for each combination of hyperparameters. The combination of hyperparameters that results in the best performance is chosen as the final set of hyperparameters. The main drawback of grid search is that it can be computationally expensive, especially when the number of hyperparameters is large.
Random Search
Random search is another simple and straightforward technique for hyperparameter optimization. In random search, a range of hyperparameters is defined, and random values are sampled from the range for each iteration. The model is trained and evaluated for each set of hyperparameters, and the combination of hyperparameters that results in the best performance is chosen as the final set of hyperparameters. Unlike grid search, random search is more computationally efficient as it requires fewer trials to find the best set of hyperparameters.
Bayesian Optimization
Bayesian optimization is a more sophisticated technique for hyperparameter optimization that uses Bayesian statistics to model the distribution of hyperparameters that result in the best performance. The main advantage of Bayesian optimization is that it is more efficient than grid search and random search as it utilizes information from previous trials to guide the next set of trials. Bayesian optimization is particularly useful for problems where the cost of evaluating the model is high.
Gradient-Based Optimization
Gradient-based optimization is a technique for hyperparameter optimization that utilizes the gradient information from the training process. The idea is to update the hyperparameters in the direction of the gradient, so as to minimize the loss function. Gradient-based optimization can be faster and more efficient than grid search, random search, and Bayesian optimization, especially when the number of hyperparameters is small.
Conclusion
In conclusion, hyperparameter optimization is a crucial step in the machine learning modeling process that can significantly impact the performance of the model. There are various hyperparameter optimization techniques available, each with its own advantages and disadvantages. Grid search and random search are simple and effective methods, while Bayesian optimization and gradient-based optimization are more advanced methods that can provide better results. However, it's important to note that the best optimization technique will depend on the specific requirements of the project and the type of model being used.
Moreover, it's essential to keep in mind that hyperparameter optimization is not a one-time process. As data and requirements change, it may be necessary to re-optimize the model to ensure it remains effective. Additionally, it's important to keep a record of the optimization process, including the hyperparameters used, the results obtained, and the reasoning behind the choices made.
Takeaway Notes
In summary, hyperparameter optimization is an essential aspect of the machine learning modeling process that can significantly impact model performance. By carefully considering the various optimization techniques available, data scientists can choose the best approach to achieve their desired outcomes and produce high-quality models.