Semi-Supervised Learning in Machine Learning: Approaches and Applications




Photo by Joshua Reddekopp on Unsplash
Introduction
Machine learning is a field of artificial intelligence that involves building algorithms that can automatically improve their performance over time. One of the fundamental approaches in machine learning is supervised learning, where the algorithm is trained on a labeled dataset to predict the output given a set of inputs. However, obtaining labeled data can be expensive and time-consuming. This is where semi-supervised learning comes in, as it provides a solution to this problem by leveraging both labeled and unlabeled data.
What is Semi-Supervised Learning?
Semi-supervised learning is a machine learning approach that combines both labeled and unlabeled data to train a model.
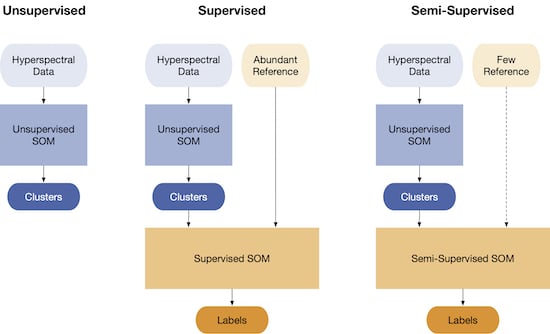
Image Link: link
The goal is to leverage the large amounts of unlabeled data that is often readily available to improve the performance of the model. In a semi-supervised learning setting, the algorithm uses the labeled data to learn the mapping from inputs to outputs and then applies that mapping to the unlabeled data to make predictions.
Approaches in Semi-Supervised Learning
There are several approaches to semi-supervised learning, each with its own strengths and limitations. Some of the most commonly used approaches are:
Self-Training:
This approach involves training a model on the labeled data and then using the model to label the unlabeled data. The newly labeled data is then combined with the original labeled data and used to retrain the model. This process is repeated until the model has stabilized.
Co-training:
This approach involves training two separate models on the labeled data, each model focusing on different aspects of the data. The models are then used to label the unlabeled data, and the newly labeled data is combined with the original labeled data and used to retrain the models.
Multi-view learning:
In this approach, multiple models are trained on different representations of the same data. For example, a model could be trained on the text representation of the data while another model is trained on the image representation of the same data. The models are then combined to make predictions.
Generative Adversarial Networks (GANs):
GANs are a type of semi-supervised learning approach that involves training a generator and a discriminator. The generator creates synthetic data that is used to augment the labeled data, while the discriminator tries to distinguish between the real and synthetic data. Over time, the generator improves its ability to generate synthetic data that is similar to real data, leading to improved model accuracy.
Graph-based methods:
Graph-based methods involve constructing a graph representation of the data, where each data point is represented as a node in the graph and edges are created between similar data points. The graph is then used to propagate labels from the labeled data to the unlabeled data, allowing the model to make predictions on the unlabeled data.
These are just a few of the many approaches to semi-supervised learning, and the choice of approach will depend on the specific problem and data being used. Regardless of the approach chosen, the goal of semi-supervised learning is to leverage the information contained within the unlabeled data to improve the accuracy of models and overcome the limitations of traditional supervised learning.
Applications of Semi-Supervised Learning
Semi-supervised learning has a wide range of applications in various industries and domains. Some of the most prominent applications of semi-supervised learning are as follows:
Text Classification:
Image Source: link
Semi-supervised learning is commonly used in text classification tasks, where a large amount of unlabeled text data is available. By leveraging the information contained within the unlabeled data, semi-supervised learning can improve the accuracy of text classification models.
Image Classification:
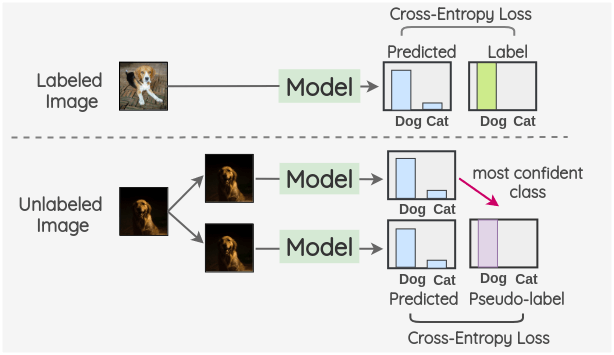
Image Source: Link
Similarly, semi-supervised learning can be applied to image classification tasks where large amounts of unlabeled images are available. By incorporating the information contained within these images, semi-supervised learning can help improve the accuracy of image classification models.
Anomaly Detection:
Semi-supervised learning is also useful in the detection of anomalies in large datasets. By combining labeled and unlabeled data, semi-supervised learning can help detect outliers in the data and identify potential anomalies more accurately.
Fraud Detection:
Fraud detection is another important application of semi-supervised learning. By combining labeled data on past fraud cases and unlabeled data on transactions, semi-supervised learning can help identify potential fraud cases more accurately.
Healthcare:
Semi-supervised learning is also useful in the healthcare industry. For example, it can be used to classify medical images such as X-rays or MRIs or to predict the likelihood of a patient developing a particular disease based on their medical history and test results.
These are just a few examples of the many applications of semi-supervised learning. As this field continues to evolve and mature, it is likely that even more innovative applications will emerge, further solidifying its importance and impact on a wide range of industries and domains.
Conclusion
Semi-supervised learning is a promising field within machine learning that has the potential to revolutionize the way we approach problems and make predictions. By combining both labeled and unlabeled data, it can leverage the strengths of both supervised and unsupervised learning to improve the accuracy of models and overcome the limitations of traditional supervised learning.
However, it is important to note that semi-supervised learning is not a one-size-fits-all solution, and the choice of approach and application will depend on the specific problem and data being used. Furthermore, as with any machine learning technique, careful consideration must be given to the quality of the data and the potential for bias and overfitting.
Parting Notes
In conclusion, semi-supervised learning is a field with a wealth of potential and opportunities. By understanding its approaches and applications, data scientists and machine learning practitioners can unlock its potential and bring about innovative solutions to complex problems. With its ability to handle large amounts of data and improve model accuracy, semi-supervised learning is a field worth exploring for anyone looking to drive progress and innovation in the world of artificial intelligence.
Thanks For Reading...!!!
You can follow me on Twitter.